
pAcGFP1-Mito
pAcGFP1-Mito
编号 | 载体名称 |
北京华越洋生物VECT6053 | pAcGFP1-Mito |
pAcGFP1-Mito载体基本信息
载体名称: | pAcGFP1-Mito |
质粒类型: | 哺乳动物细胞表达载体;荧光报告载体;亚细胞定位载体 |
高拷贝/低拷贝: | 高拷贝 |
克隆方法: | 限制性内切酶,多克隆位点 |
启动子: | CMV IE |
载体大小: | 4.8 kb |
5' 测序引物及序列: | -- |
3' 测序引物及序列: | -- |
载体标签: | -- |
载体抗性: | 卡那霉素 |
筛选标记: | 新霉素(Neomycin) |
克隆菌株: | DH5α, HB101 |
宿主细胞(系): | 常规细胞系(293、CV-1、CHO等) |
备注: | 哺乳动物载体pAcGFP1-Mito组成型表达AcGFP,是线粒体定位载体。 |
稳定性: | 稳表达 或 瞬表达 |
组成型/诱导型: | 组成型 |
病毒/非病毒: | 非病毒 |
pAcGFP1-Mito载体质粒图谱和多克隆位点信息
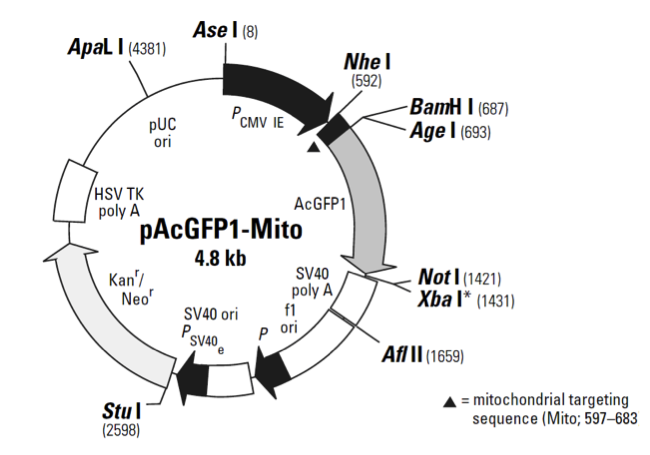

pAcGFP1-Mito载体简介
pAcGFP1-Mito encodes a fusion of a mitochondrial targeting sequence derived from the precursor of subunit VIII of human cytochrome C oxidase (1, 2) and the green fluorescent protein (GFP) from Aequorea coerulescens (AcGFP1; excitation maximum = 475 nm; emission maximum = 505 nm). The mitochondrial targeting sequence is fused to the N-terminus of AcGFP1. AcGFP1 contains silent mutations that create an open reading frame comprised almost entirely of optimized human codons. These changes increase the translational efficiency of the AcGFP1 mRNA and, consequently, the expression of AcGFP1 in mammalian and plant cells. The vector contains an SV40 origin for replication and a neomycin resistance (Neor) gene for selection (using G418) in eukaryotic cells (3). A bacterial promoter (P) upstream of Neor expresses kanamycin resistance in E. coli. The vector backbone also provides a pUC origin of replication for propagation in E. coli and an f1 origin for single-stranded DNA production.
pAcGFP1-Mito is designed for fluorescent labeling of mitochondria. The fluorescence from pAcGFP1-Mito expression can be observed within the mitochondrial matrix inside the inner membrane. pAcGFP1-Mito can be introduced into mammalian cells using any standard transfection method. If required, stable transformants can be selected using G418 (3). pAcGFP1- Mito is not intended as a cloning vector; however, the backbone does contain unique restriction sites upstream and downstream of the AcGFP1-Mito sequence which permit excision of the AcGFP1-Mito sequence.
Propagation in E. coli
Suitable host strains: DH5α, HB101, and other general purpose strains. Single-stranded DNA production requires a host such as JM109 or XL1-Blue that contains an F plasmid .
Selectable marker: plasmid confers resistance to kanamycin (50 μg/ml) to E. coli hosts.
E. coli replication origin: pUC
Copy number: ≈500
Plasmid incompatibility group: pMB1/ColE1
pAcGFP1-Mito载体序列
ORIGIN
1 TAGTTATTAA TAGTAATCAA TTACGGGGTC ATTAGTTCAT AGCCCATATA TGGAGTTCCG
61 CGTTACATAA CTTACGGTAA ATGGCCCGCC TGGCTGACCG CCCAACGACC CCCGCCCATT
121 GACGTCAATA ATGACGTATG TTCCCATAGT AACGCCAATA GGGACTTTCC ATTGACGTCA
181 ATGGGTGGAG TATTTACGGT AAACTGCCCA CTTGGCAGTA CATCAAGTGT ATCATATGCC
241 AAGTACGCCC CCTATTGACG TCAATGACGG TAAATGGCCC GCCTGGCATT ATGCCCAGTA
301 CATGACCTTA TGGGACTTTC CTACTTGGCA GTACATCTAC GTATTAGTCA TCGCTATTAC
361 CATGGTGATG CGGTTTTGGC AGTACATCAA TGGGCGTGGA TAGCGGTTTG ACTCACGGGG
421 ATTTCCAAGT CTCCACCCCA TTGACGTCAA TGGGAGTTTG TTTTGGCACC AAAATCAACG
481 GGACTTTCCA AAATGTCGTA ACAACTCCGC CCCATTGACG CAAATGGGCG GTAGGCGTGT
541 ACGGTGGGAG GTCTATATAA GCAGAGCTGG TTTAGTGAAC CGTCAGATCC GCTAGCATGT
601 CCGTCCTGAC GCCGCTGCTG CTGCGGGGCT TGACAGGCTC GGCCCGGCGG CTCCCAGTGC
661 CGCGCGCCAA GATCCATTCG TTGGGGGATC CACCGGTCAT GGTGAGCAAG GGCGCCGAGC
721 TGTTCACCGG CATCGTGCCC ATCCTGATCG AGCTGAATGG CGATGTGAAT GGCCACAAGT
781 TCAGCGTGAG CGGCGAGGGC GAGGGCGATG CCACCTACGG CAAGCTGACC CTGAAGTTCA
841 TCTGCACCAC CGGCAAGCTG CCTGTGCCCT GGCCCACCCT GGTGACCACC CTGAGCTACG
901 GCGTGCAGTG CTTCTCACGC TACCCCGATC ACATGAAGCA GCACGACTTC TTCAAGAGCG
961 CCATGCCTGA GGGCTACATC CAGGAGCGCA CCATCTTCTT CGAGGATGAC GGCAACTACA
1021 AGTCGCGCGC CGAGGTGAAG TTCGAGGGCG ATACCCTGGT GAATCGCATC GAGCTGACCG
1081 GCACCGATTT CAAGGAGGAT GGCAACATCC TGGGCAATAA GATGGAGTAC AACTACAACG
1141 CCCACAATGT GTACATCATG ACCGACAAGG CCAAGAATGG CATCAAGGTG AACTTCAAGA
1201 TCCGCCACAA CATCGAGGAT GGCAGCGTGC AGCTGGCCGA CCACTACCAG CAGAATACCC
1261 CCATCGGCGA TGGCCCTGTG CTGCTGCCCG ATAACCACTA CCTGTCCACC CAGAGCGCCC
1321 TGTCCAAGGA CCCCAACGAG AAGCGCGATC ACATGATCTA CTTCGGCTTC GTGACCGCCG
1381 CCGCCATCAC CCACGGCATG GATGAGCTGT ACAAGTGAGC GGCCGCGACT CTAGATCATA
1441 ATCAGCCATA CCACATTTGT AGAGGTTTTA CTTGCTTTAA AAAACCTCCC ACACCTCCCC
1501 CTGAACCTGA AACATAAAAT GAATGCAATT GTTGTTGTTA ACTTGTTTAT TGCAGCTTAT
1561 AATGGTTACA AATAAAGCAA TAGCATCACA AATTTCACAA ATAAAGCATT TTTTTCACTG
1621 CATTCTAGTT GTGGTTTGTC CAAACTCATC AATGTATCTT AAGGCGTAAA TTGTAAGCGT
1681 TAATATTTTG TTAAAATTCG CGTTAAATTT TTGTTAAATC AGCTCATTTT TTAACCAATA
1741 GGCCGAAATC GGCAAAATCC CTTATAAATC AAAAGAATAG ACCGAGATAG GGTTGAGTGT
1801 TGTTCCAGTT TGGAACAAGA GTCCACTATT AAAGAACGTG GACTCCAACG TCAAAGGGCG
1861 AAAAACCGTC TATCAGGGCG ATGGCCCACT ACGTGAACCA TCACCCTAAT CAAGTTTTTT
1921 GGGGTCGAGG TGCCGTAAAG CACTAAATCG GAACCCTAAA GGGAGCCCCC GATTTAGAGC
1981 TTGACGGGGA AAGCCGGCGA ACGTGGCGAG AAAGGAAGGG AAGAAAGCGA AAGGAGCGGG
2041 CGCTAGGGCG CTGGCAAGTG TAGCGGTCAC GCTGCGCGTA ACCACCACAC CCGCCGCGCT
2101 TAATGCGCCG CTACAGGGCG CGTCAGGTGG CACTTTTCGG GGAAATGTGC GCGGAACCCC
2161 TATTTGTTTA TTTTTCTAAA TACATTCAAA TATGTATCCG CTCATGAGAC AATAACCCTG
2221 ATAAATGCTT CAATAATATT GAAAAAGGAA GAGTCCTGAG GCGGAAAGAA CCAGCTGTGG
2281 AATGTGTGTC AGTTAGGGTG TGGAAAGTCC CCAGGCTCCC CAGCAGGCAG AAGTATGCAA
2341 AGCATGCATC TCAATTAGTC AGCAACCAGG TGTGGAAAGT CCCCAGGCTC CCCAGCAGGC
2401 AGAAGTATGC AAAGCATGCA TCTCAATTAG TCAGCAACCA TAGTCCCGCC CCTAACTCCG
2461 CCCATCCCGC CCCTAACTCC GCCCAGTTCC GCCCATTCTC CGCCCCATGG CTGACTAATT
2521 TTTTTTATTT ATGCAGAGGC CGAGGCCGCC TCGGCCTCTG AGCTATTCCA GAAGTAGTGA
2581 GGAGGCTTTT TTGGAGGCCT AGGCTTTTGC AAAGATCGAT CAAGAGACAG GATGAGGATC
2641 GTTTCGCATG ATTGAACAAG ATGGATTGCA CGCAGGTTCT CCGGCCGCTT GGGTGGAGAG
2701 GCTATTCGGC TATGACTGGG CACAACAGAC AATCGGCTGC TCTGATGCCG CCGTGTTCCG
2761 GCTGTCAGCG CAGGGGCGCC CGGTTCTTTT TGTCAAGACC GACCTGTCCG GTGCCCTGAA
2821 TGAACTGCAA GACGAGGCAG CGCGGCTATC GTGGCTGGCC ACGACGGGCG TTCCTTGCGC
2881 AGCTGTGCTC GACGTTGTCA CTGAAGCGGG AAGGGACTGG CTGCTATTGG GCGAAGTGCC
2941 GGGGCAGGAT CTCCTGTCAT CTCACCTTGC TCCTGCCGAG AAAGTATCCA TCATGGCTGA
3001 TGCAATGCGG CGGCTGCATA CGCTTGATCC GGCTACCTGC CCATTCGACC ACCAAGCGAA
3061 ACATCGCATC GAGCGAGCAC GTACTCGGAT GGAAGCCGGT CTTGTCGATC AGGATGATCT
3121 GGACGAAGAG CATCAGGGGC TCGCGCCAGC CGAACTGTTC GCCAGGCTCA AGGCGAGCAT
3181 GCCCGACGGC GAGGATCTCG TCGTGACCCA TGGCGATGCC TGCTTGCCGA ATATCATGGT
3241 GGAAAATGGC CGCTTTTCTG GATTCATCGA CTGTGGCCGG CTGGGTGTGG CGGACCGCTA
3301 TCAGGACATA GCGTTGGCTA CCCGTGATAT TGCTGAAGAG CTTGGCGGCG AATGGGCTGA
3361 CCGCTTCCTC GTGCTTTACG GTATCGCCGC TCCCGATTCG CAGCGCATCG CCTTCTATCG
3421 CCTTCTTGAC GAGTTCTTCT GAGCGGGACT CTGGGGTTCG AAATGACCGA CCAAGCGACG
3481 CCCAACCTGC CATCACGAGA TTTCGATTCC ACCGCCGCCT TCTATGAAAG GTTGGGCTTC
3541 GGAATCGTTT TCCGGGACGC CGGCTGGATG ATCCTCCAGC GCGGGGATCT CATGCTGGAG
3601 TTCTTCGCCC ACCCTAGGGG GAGGCTAACT GAAACACGGA AGGAGACAAT ACCGGAAGGA
3661 ACCCGCGCTA TGACGGCAAT AAAAAGACAG AATAAAACGC ACGGTGTTGG GTCGTTTGTT
3721 CATAAACGCG GGGTTCGGTC CCAGGGCTGG CACTCTGTCG ATACCCCACC GAGACCCCAT
3781 TGGGGCCAAT ACGCCCGCGT TTCTTCCTTT TCCCCACCCC ACCCCCCAAG TTCGGGTGAA
3841 GGCCCAGGGC TCGCAGCCAA CGTCGGGGCG GCAGGCCCTG CCATAGCCTC AGGTTACTCA
3901 TATATACTTT AGATTGATTT AAAACTTCAT TTTTAATTTA AAAGGATCTA GGTGAAGATC
3961 CTTTTTGATA ATCTCATGAC CAAAATCCCT TAACGTGAGT TTTCGTTCCA CTGAGCGTCA
4021 GACCCCGTAG AAAAGATCAA AGGATCTTCT TGAGATCCTT TTTTTCTGCG CGTAATCTGC
4081 TGCTTGCAAA CAAAAAAACC ACCGCTACCA GCGGTGGTTT GTTTGCCGGA TCAAGAGCTA
4141 CCAACTCTTT TTCCGAAGGT AACTGGCTTC AGCAGAGCGC AGATACCAAA TACTGTTCTT
4201 CTAGTGTAGC CGTAGTTAGG CCACCACTTC AAGAACTCTG TAGCACCGCC TACATACCTC
4261 GCTCTGCTAA TCCTGTTACC AGTGGCTGCT GCCAGTGGCG ATAAGTCGTG TCTTACCGGG
4321 TTGGACTCAA GACGATAGTT ACCGGATAAG GCGCAGCGGT CGGGCTGAAC GGGGGGTTCG
4381 TGCACACAGC CCAGCTTGGA GCGAACGACC TACACCGAAC TGAGATACCT ACAGCGTGAG
4441 CTATGAGAAA GCGCCACGCT TCCCGAAGGG AGAAAGGCGG ACAGGTATCC GGTAAGCGGC
4501 AGGGTCGGAA CAGGAGAGCG CACGAGGGAG CTTCCAGGGG GAAACGCCTG GTATCTTTAT
4561 AGTCCTGTCG GGTTTCGCCA CCTCTGACTT GAGCGTCGAT TTTTGTGATG CTCGTCAGGG
4621 GGGCGGAGCC TATGGAAAAA CGCCAGCAAC GCGGCCTTTT TACGGTTCCT GGCCTTTTGC
4681 TGGCCTTTTG CTCACATGTT CTTTCCTGCG TTATCCCCTG ATTCTGTGGA TAACCGTATT
4741 ACCGCCATGC AT
//
其他哺乳动物表达载体:
pcDNA6.2/nGeneBLAzer-GW/D-TOPO |
