
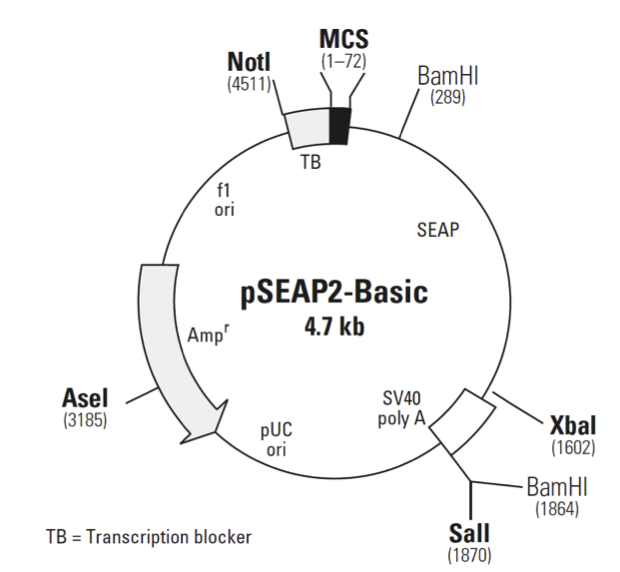
pSEAP2-Basic
pSEAP2-Basic
编号 | 载体名称 |
北京华越洋生物VECT6050 | pSEAP2-Basic |
pSEAP2-Basic载体基本信息
载体名称: | pSEAP2-Basic |
质粒类型: | 哺乳动物细胞表达载体;无启动子载体;分泌型碱性磷酸酶报告载体 |
高拷贝/低拷贝: | 高拷贝 |
克隆方法: | 限制性内切酶,多克隆位点 |
启动子: | 无 |
载体大小: | 4677 bp |
5' 测序引物及序列: | 5'-CTAGCAAAATAGGCTGTCCC-3' |
3' 测序引物及序列: | 5'-CCTCGGCTGCCTCGCGGTTCC-3' |
载体标签: | -- |
载体抗性: | 氨苄青霉素 |
筛选标记: | 无 |
克隆菌株: | DH5α 等通用菌株 |
宿主细胞(系): | 常规细胞系(293、CV-1、CHO等) |
备注: | 哺乳动物细胞表达载体pSEAP2-Basic没有启动子元件; |
稳定性: | 瞬表达 |
组成型/诱导型: | -- |
病毒/非病毒: | 非病毒 |
pSEAP2-Basic载体质粒图谱和多克隆位点信息



pSEAP2-Basic载体描述
pSEAP2-Basic allows for expression of the reporter gene secreted alkaline phosphatase (SEAP). This vector lacks eukaryotic promoter and enhancer sequences and has an MCS that allows putative promoter DNA fragments to be inserted upstream of the SEAP gene. Enhancers can be cloned into either the MCS or unique downstream sites. The SEAP coding sequence is followed by the SV40 late polyadenylation signal to ensure proper, efficient processing of the SEAP transcript in eukaryotic cells. A synthetic transcription blocker (TB), composed of adjacent polyadenylation and transcription pause sites, located upstream of the MCS reduces background transcription (1). The vector backbone also contains an f1 origin for single-stranded DNA production, a pUC origin of replication, and an ampicillin resistance gene for propagation and selection in E. coli. The SEAP2 Vectors incorporate a number of features that improve the sensitivity of SEAP by increaing the efficiency of SEAP expression or that enhance the utility of the vectors. These include: an improved Kozak consensus translation initiation site (2); the removal of the SV40 small-t intron, which can cause cryptic splicing and reduced expression in some genes and/or cell types (3, 4); switching from the early to late polyadenylation signal of SV40, which typically causes a five-fold increase in mRNA levels (5); an expanded multiple cloning site (MCS); compact plasmid size; and removal of extraneous sequences from the 3' untranslated region of the SEAP mRNA.
The integrated set of Great EscAPe? SEAP2 Vectors has been designed to provide maximal flexibility in studying regulatory sequences from the gene of interest. pSEAP2-Basic allows for expression of SEAP under control of putative promoters and/or enhancers of interest. The secreted SEAP enzyme is assayed directly from the culture medium and permits time-course studies not possible with assays dependent on cell lysates. Furthermore, the cells can be used for further investigations such as RNA or protein studies. The SEAP2 Vectors can be transfected into mammalian cells by any standard method.
Propagation in E. coli
Suitable host strains: DH5α and other general purpose strains. Single-stranded DNA production requires a host containing an F' episome such as JM109.
Selectable marker: plasmid confers resistance to ampicillin (100 μg/ml) to E. coli hosts.
E. coli replication origin: pUC
Copy number: ~500
Plasmid incompatibility group: pMB1/Col E1
References:
1. Eggermont, J. & Proudfoot, N. (1993) EMBO J. 12:2539–2548.
2. Kozak, M. (1987) Nucleic Acids Res. 15:8125–8148.
3. Huang, M. T. F. & Gorman, C. M. (1990) Mol. Cell. Biol. 10:1805–1810.
4. Evans, M. J. & Scarpulla, R. C. (1989) Gene 84:135–142.
5. Carswell, S. & Alwine, J. C. (1989) Mol. Cell. Biol. 9:4248–4258.
6. Levitt, N. et al. (1989) Genes Dev. 3:1019–1025.
7. Enriquez-Harris, P. et al. (1991) EMBO J. 10:1833–1842.
Note: The attached sequence file has been compiled from information in the sequence databases, published literature, and other sources, together with partial sequences obtained by Clontech. This vector has not been completely sequenced
载体序列
ORIGIN
1 GGTACCGAGC TCTTACGCGT GCTAGCCCGG GCTCGAGATC TGCGATCTAA GTAAGCTTCG
61 AATCGCGAAT TCGCCCACCA TGCTGCTGCT GCTGCTGCTG CTGGGCCTGA GGCTACAGCT
121 CTCCCTGGGC ATCATCCCAG TTGAGGAGGA GAACCCGGAC TTCTGGAACC GCGAGGCAGC
181 CGAGGCCCTG GGTGCCGCCA AGAAGCTGCA GCCTGCACAG ACAGCCGCCA AGAACCTCAT
241 CATCTTCCTG GGCGATGGGA TGGGGGTGTC TACGGTGACA GCTGCCAGGA TCCTAAAAGG
301 GCAGAAGAAG GACAAACTGG GGCCTGAGAT ACCCCTGGCC ATGGACCGCT TCCCATATGT
361 GGCTCTGTCC AAGACATACA ATGTAGACAA ACATGTGCCA GACAGTGGAG CCACAGCCAC
421 GGCCTACCTG TGCGGGGTCA AGGGCAACTT CCAGACCATT GGCTTGAGTG CAGCCGCCCG
481 CTTTAACCAG TGCAACACGA CACGCGGCAA CGAGGTCATC TCCGTGATGA ATCGGGCCAA
541 GAAAGCAGGG AAGTCAGTGG GAGTGGTAAC CACCACACGA GTGCAGCACG CCTCGCCAGC
601 CGGCACCTAC GCCCACACGG TGAACCGCAA CTGGTACTCG GACGCCGACG TGCCTGCCTC
661 GGCCCGCCAG GAGGGGTGCC AGGACATCGC TACGCAGCTC ATCTCCAACA TGGACATTGA
721 CGTGATCCTA GGTGGAGGCC GAAAGTACAT GTTTCGCATG GGAACCCCAG ACCCTGAGTA
781 CCCAGATGAC TACAGCCAAG GTGGGACCAG GCTGGACGGG AAGAATCTGG TGCAGGAATG
841 GCTGGCGAAG CGCCAGGGTG CCCGGTATGT GTGGAACCGC ACTGAGCTCA TGCAGGCTTC
901 CCTGGACCCG TCTGTGACCC ATCTCATGGG TCTCTTTGAG CCTGGAGACA TGAAATACGA
961 GATCCACCGA GACTCCACAC TGGACCCCTC CCTGATGGAG ATGACAGAGG CTGCCCTGCG
1021 CCTGCTGAGC AGGAACCCCC GCGGCTTCTT CCTCTTCGTG GAGGGTGGTC GCATCGACCA
1081 TGGTCATCAT GAAAGCAGGG CTTACCGGGC ACTGACTGAG ACGATCATGT TCGACGACGC
1141 CATTGAGAGG GCGGGCCAGC TCACCAGCGA GGAGGACACG CTGAGCCTCG TCACTGCCGA
1201 CCACTCCCAC GTCTTCTCCT TCGGAGGCTA CCCCCTGCGA GGGAGCTCCA TCTTCGGGCT
1261 GGCCCCTGGC AAGGCCCGGG ACAGGAAGGC CTACACGGTC CTCCTATACG GAAACGGTCC
1321 AGGCTATGTG CTCAAGGACG GCGCCCGGCC GGATGTTACC GAGAGCGAGA GCGGGAGCCC
1381 CGAGTATCGG CAGCAGTCAG CAGTGCCCCT GGACGAAGAG ACCCACGCAG GCGAGGACGT
1441 GGCGGTGTTC GCGCGCGGCC CGCAGGCGCA CCTGGTTCAC GGCGTGCAGG AGCAGACCTT
1501 CATAGCGCAC GTCATGGCCT TCGCCGCCTG CCTGGAGCCC TACACCGCCT GCGACCTGGC
1561 GCCCCCCGCC GGCACCACCG ACGCCGCGCA CCCGGGTTAC TCTAGAGTCG GGGCGGCCGG
1621 CCGCTTCGAG CAGACATGAT AAGATACATT GATGAGTTTG GACAAACCAC AACTAGAATG
1681 CAGTGAAAAA AATGCTTTAT TTGTGAAATT TGTGATGCTA TTGCTTTATT TGTAACCATT
1741 ATAAGCTGCA ATAAACAAGT TAACAACAAC AATTGCATTC ATTTTATGTT TCAGGTTCAG
1801 GGGGAGGTGT GGGAGGTTTT TTAAAGCAAG TAAAACCTCT ACAAATGTGG TAAAATCGAT
1861 AAGGATCCGT CGACCGATGC CCTTGAGAGC CTTCAACCCA GTCAGCTCCT TCCGGTGGGC
1921 GCGGGGCATG ACTATCGTCG CCGCACTTAT GACTGTCTTC TTTATCATGC AACTCGTAGG
1981 ACAGGTGCCG GCAGCGCTCT TCCGCTTCCT CGCTCACTGA CTCGCTGCGC TCGGTCGTTC
2041 GGCTGCGGCG AGCGGTATCA GCTCACTCAA AGGCGGTAAT ACGGTTATCC ACAGAATCAG
2101 GGGATAACGC AGGAAAGAAC ATGTGAGCAA AAGGCCAGCA AAAGGCCAGG AACCGTAAAA
2161 AGGCCGCGTT GCTGGCGTTT TTCCATAGGC TCCGCCCCCC TGACGAGCAT CACAAAAATC
2221 GACGCTCAAG TCAGAGGTGG CGAAACCCGA CAGGACTATA AAGATACCAG GCGTTTCCCC
2281 CTGGAAGCTC CCTCGTGCGC TCTCCTGTTC CGACCCTGCC GCTTACCGGA TACCTGTCCG
2341 CCTTTCTCCC TTCGGGAAGC GTGGCGCTTT CTCATAGCTC ACGCTGTAGG TATCTCAGTT
2401 CGGTGTAGGT CGTTCGCTCC AAGCTGGGCT GTGTGCACGA ACCCCCCGTT CAGCCCGACC
2461 GCTGCGCCTT ATCCGGTAAC TATCGTCTTG AGTCCAACCC GGTAAGACAC GACTTATCGC
2521 CACTGGCAGC AGCCACTGGT AACAGGATTA GCAGAGCGAG GTATGTAGGC GGTGCTACAG
2581 AGTTCTTGAA GTGGTGGCCT AACTACGGCT ACACTAGAAG AACAGTATTT GGTATCTGCG
2641 CTCTGCTGAA GCCAGTTACC TTCGGAAAAA GAGTTGGTAG CTCTTGATCC GGCAAACAAA
2701 CCACCGCTGG TAGCGGTGGT TTTTTTGTTT GCAAGCAGCA GATTACGCGC AGAAAAAAAG
2761 GATCTCAAGA AGATCCTTTG ATCTTTTCTA CGGGGTCTGA CGCTCAGTGG AACGAAAACT
2821 CACGTTAAGG GATTTTGGTC ATGAGATTAT CAAAAAGGAT CTTCACCTAG ATCCTTTTAA
2881 ATTAAAAATG AAGTTTTAAA TCAATCTAAA GTATATATGA GTAAACTTGG TCTGACAGTT
2941 ACCAATGCTT AATCAGTGAG GCACCTATCT CAGCGATCTG TCTATTTCGT TCATCCATAG
3001 TTGCCTGACT CCCCGTCGTG TAGATAACTA CGATACGGGA GGGCTTACCA TCTGGCCCCA
3061 GTGCTGCAAT GATACCGCGA GACCCACGCT CACCGGCTCC AGATTTATCA GCAATAAACC
3121 AGCCAGCCGG AAGGGCCGAG CGCAGAAGTG GTCCTGCAAC TTTATCCGCC TCCATCCAGT
3181 CTATTAATTG TTGCCGGGAA GCTAGAGTAA GTAGTTCGCC AGTTAATAGT TTGCGCAACG
3241 TTGTTGCCAT TGCTACAGGC ATCGTGGTGT CACGCTCGTC GTTTGGTATG GCTTCATTCA
3301 GCTCCGGTTC CCAACGATCA AGGCGAGTTA CATGATCCCC CATGTTGTGC AAAAAAGCGG
3361 TTAGCTCCTT CGGTCCTCCG ATCGTTGTCA GAAGTAAGTT GGCCGCAGTG TTATCACTCA
3421 TGGTTATGGC AGCACTGCAT AATTCTCTTA CTGTCATGCC ATCCGTAAGA TGCTTTTCTG
3481 TGACTGGTGA GTACTCAACC AAGTCATTCT GAGAATAGTG TATGCGGCGA CCGAGTTGCT
3541 CTTGCCCGGC GTCAATACGG GATAATACCG CGCCACATAG CAGAACTTTA AAAGTGCTCA
3601 TCATTGGAAA ACGTTCTTCG GGGCGAAAAC TCTCAAGGAT CTTACCGCTG TTGAGATCCA
3661 GTTCGATGTA ACCCACTCGT GCACCCAACT GATCTTCAGC ATCTTTTACT TTCACCAGCG
3721 TTTCTGGGTG AGCAAAAACA GGAAGGCAAA ATGCCGCAAA AAAGGGAATA AGGGCGACAC
3781 GGAAATGTTG AATACTCATA CTCTTCCTTT TTCAATATTA TTGAAGCATT TATCAGGGTT
3841 ATTGTCTCAT GAGCGGATAC ATATTTGAAT GTATTTAGAA AAATAAACAA ATAGGGGTTC
3901 CGCGCACATT TCCCCGAAAA GTGCCACCTG ACGCGCCCTG TAGCGGCGCA TTAAGCGCGG
3961 CGGGTGTGGT GGTTACGCGC AGCGTGACCG CTACACTTGC CAGCGCCCTA GCGCCCGCTC
4021 CTTTCGCTTT CTTCCCTTCC TTTCTCGCCA CGTTCGCCGG CTTTCCCCGT CAAGCTCTAA
4081 ATCGGGGGCT CCCTTTAGGG TTCCGATTTA GTGCTTTACG GCACCTCGAC CCCAAAAAAC
4141 TTGATTAGGG TGATGGTTCA CGTAGTGGGC CATCGCCCTG ATAGACGGTT TTTCGCCCTT
4201 TGACGTTGGA GTCCACGTTC TTTAATAGTG GACTCTTGTT CCAAACTGGA ACAACACTCA
4261 ACCCTATCTC GGTCTATTCT TTTGATTTAT AAGGGATTTT GCCGATTTCG GCCTATTGGT
4321 TAAAAAATGA GCTGATTTAA CAAAAATTTA ACGCGAATTT TAACAAAATA TTAACGCTTA
4381 CAATTTGCCA TTCGCCATTC AGGCTGCGCA ACTGTTGGGA AGGGCGATCG GTGCGGGCCT
4441 CTTCGCTATT ACGCCAGCCC AAGCTACCAT GATAAGTAAG TAATATTAAG GTACGGGAGG
4501 TACTTGGAGC GGCCGCAATA AAATATCTTT ATTTTCATTA CATCTGTGTG TTGGTTTTTT
4561 GTGTGAATCG ATAGTACTAA CATACGCTCT CCATCAAAAC AAAACGAAAC AAAACAAACT
4621 AGCAAAATAG GCTGTCCCCA GTGCAAGTGC AGGTGCCAGA ACATTTCTCT ATCGATA
//
其他哺乳动物表达载体:
pcDNA6.2/nGeneBLAzer-GW/D-TOPO |
